I just spotted something on the HHP leaderboard that I have not seen before. There has been no change in the top 12 positions for 1 week.
Does this mean we are all running out of ideas? Teams are submitting but the incremental improvement seems to be relatively minuscule.
Dave (He is smarter than me!) and Willem seem to have a big gap at the top, and Edward is close on my tail for 3rd place. The team I would look out for though are some Old Dogs With New Tricks.

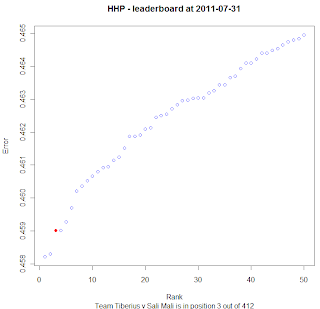
Does this mean we are all running out of ideas? Teams are submitting but the incremental improvement seems to be relatively minuscule.
Dave (He is smarter than me!) and Willem seem to have a big gap at the top, and Edward is close on my tail for 3rd place. The team I would look out for though are some Old Dogs With New Tricks.