A little progress...
- My daughter made it through her first swimming lesson without needing a swimming nappy. This was mainly my fault as we had ran out and the lesson was too early to have time to go to the shop. Anyway, that should save me some cash, so maybe I will no longer need the full 3 million.
- I managed to find a way of posting code with syntax highlighting into this blog
- I managed to load the HHP data into a database
- I picked up some bugs and improved some of my software while doing 3).
So, now the details....
1) Well done Princess no. 3
(but please tell us where you hid the TV remote)
2) Highlighting Code in a blog
When you do data mining, you would generally at some point have to write some computer code that does stuff to your data. You will notice that when you write the code it generally turns nice colours to highlight things that make the code easier to interpret.
I will hopefully be doing lots of this and posting code snippets to this blog so others can get ideas or use the exact same code to try out (not sure how this fits in with the rules of the contest, but lets go for it anyway). It would be nice if the code also coloured itself in the blog.
A Google search came up with this site
http://tohtml.com/. You just paste your code in a window, select what computer language the code is written in, press a button and presto, it generates html code for you. You then just edit the html of your blog and paste it in, and should get something like this...
Sub IsThisRight()
MsgBox (IsNumeric("50+"))
End Sub
and if you tweak the background colour by editing the html...
Sub IsThisRight()
MsgBox (IsNumeric("50+"))
End Sub
and if the code is big you can put it in a window by wrapping a div tag around in.
Sub IsThisRight()
MsgBox (IsNumeric("50+"))
End Sub
A call for help - how do I set the default font in Blogger? I can't find the option anywhere.
3) Loading the HHP data into a database
Well, at last something related to data mining...
When you are doing analytics as a consultant, you get given data files in typically 3 ways.
- an Excel spreadsheet
- some other proprietary data file format such as SAS or SPSS
- a text file that is an extract from a database
the Excel spreadsheet can be because of 2 reasons:
- Excel is the database used and where the raw data lives (worrying but very common)
- The person doing the extract extracted it from a database for you and then decided they were doing you a favour by putting in Excel to pretty it up (also worrying)
I've had the following explanations given to me...
"There were a few million rows in the database but I can only get 64,000 on each sheet of excel so it will take me a while to get it ready for you."
"I extracted it but had to put it in excel because I new some of the data was wrong so I manually edited it for you."
When you hear this, just take a deep breath and do a bit of hand holding.
You often get proprietary files sent, which basically means it can be a pain to open them if you don't have the proprietary software. These are generally binary files and are the ones that look like hieroglyphics when you try to open them in a text editor. Binary files are a more efficient format for storing and retrieving data.
The bog standard ascii text file extract is the most painless way to go, which is the way it works in Kaggle competitions. There are two ways you could get these files:
- fixed width
- character separated variables (*.csv files)
The data represents fields/variables/columns/features and rows/cases/examples. Text files are clever and know when there is a new row of data, but specifying which bit of data should be in which column is another matter.
In fixed width files, each column starts at the same place in each row. This is not necessarily best as you may have to do a lot of padding with blank spaces to get the columns aligned, which makes the file bigger. If all the data in each column has the same width, then you will get a smaller file as it saves having to put a delimiter character in there. They are also not particularly simple to load - these are the ones in Access where you have to click to tell Access where the columns need to go. The field names are also generally not on the first row, they are tucked away in some other field definition file.
CSV (C Separated Values) files put a particular character in each line to indicate where the column boundaries are. There are a few rules on how the files should be generated (note: there used to be a wikipedia entry that said csv stood for character, not comma, but I can't find this anymore - but there is a new entry DSV.)
The common character is a comma (","), but using this is fraught with danger which can lead to your file not loading properly.
If you have a text field in your data where a comma is actually contained in the text, such as address ("1 Smith St, Melbourne") the text field need to be "qu,oted" in order to determine that the comma is part of the data rather than a delimiter. If these quotes are not included your data will get stuffed up and will have to be extracted again. This happens very often.
Also, some countries use the "," as a decimal point, which can also complicate things (see here).
When receiving data, I always ask for pipe delimited (this is the pipe character | ) files with no quotes around string fields. The pipe character is unlikely to be present in any text fields (as not many people actually know what it is) so is a fair choice for a delimiter. Not including quotes around text, although this is defined in the standard, is going to be more friendly to most software you will use. Tab delimited files are also another option.
Well, enough of the side track, back to the HHP data.
When you receive a delimited text file, I recommend you check it before you do anything - don't assume it has been extracted correctly. The check is simply counting that each row has the same number of delimiters.
Now you could load it into Excel to eyeball and it might 'look right', but Excel won't deal with bad files, and your columns may become miss-aligned. I also don't trust Excel as it also seems to have a mind of its own sometimes and does things to data that you rather it wouldn't, and might not even realise it has done (try typing (22) into Excel, including the brackets. Dates are also a concern for me).
You can also load the data into numerous databases using the import wizards they provide. Now some will tell you there are issues, but not all.
Microsoft SQL Server is one example of a database that used to be good at checking things. I often got messages such as 'error at row 2,758,946' and the would go and check the file at this row and discover there was an issue. You would then have to correct that row, re-load, get the next error message, correct, re-load etc.
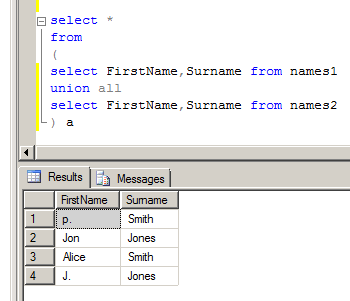
Now, in order to show you what the error message was, I tried running an example in Microsoft SQL Server 2008 R2. I used the data import wizard to load the following CSV file:
and this is what it did:
This is not what I was expecting. You will see column c, row 2 has the value 3,4. This is probably not what was intended. Now the last time I used the import wizard, in version 2000, I'm sure it would have thrown an error, so beware version changes.
Anyway, data lives in a database, and there are many free ones available. Most of the major vendors offer free versions that have limitations on the size of the database, and there are also open source ones, see this list.
I am going to use MS SQL Server 2008 R2 which is free. It has a 10 gig limit per database, but you can create multiple databases and communicate between them, so unless you have a really massive file it should accommodate most needs. Installation from what I remember had a few tricky questions you probably will think 'what the **** is that on about' if you are not used to database lingo, but once installed it is a pretty user friendly tool.
In order to load the data, you can use the data import wizard, but this is not something I personally like. I like to run scripts, which are sets of instructions from a file, so you can readily reproduce your steps by running the script, without having to remember any manual things you did. Scripts also make you work completely portable and shareable with others so you can work in teams. As long as you have access to the raw data, you can email your bunch of scripts to your web-mail account, fly to the other side of the world and reproduce the exact steps without having to take your computer with you. This is also why it is nice to use software that is free and downloadable from the internet.
As I needed to frequently check files and automatically generate scripts to load the data, I wrote a tool (niftytools.exe, windows only) that has been a massive time saver. This checks the file, corrects dogy rows or removes them and generates the script to load data into SQL Server.
Here it is in use on the claims data,
and this is the script it generated for loading the data,
CREATE DATABASE HHP
USE HHP
CREATE TABLE Claims
(
MemberID int -- varchar(8) --integers starting with 0, could be text!
, ProviderID int -- varchar(7) --integers starting with 0, could be text!
, Vendor int -- varchar(6) --integers starting with 0, could be text!
, PCP int -- varchar(5) --integers starting with 0, could be text!
, Year varchar(2)
, Specialty varchar(25)
, PlaceSvc varchar(19)
, PayDelay varchar(4)
, LengthOfStay varchar(10)
, DSFS varchar(12)
, PrimaryConditionGroup varchar(8)
, CharlsonIndex varchar(3)
, ProcedureGroup varchar(4)
, SupLOS tinyint
)
BULK INSERT Claims
FROM 'E:\comps\hhp\raw data\HHP_release2\Claims.csv'
WITH
(
MAXERRORS = 0,
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
)
Note it has determined the maximum size the varchar (variable length character) fields need to be for optimal size, which makes the database as small as possible. It also determines what type of integer is most efficient. You will see that the tinyint is not coloured, which is because this is a relatively new datatype and the web page mentioned earlier that did this syntax highlighting obviously hasn't got it in its list of special words. I emailed the developer, so we shall see if it changes. Also the field name Year is highlighted because it as also a reserved word in SQL Server. When this happens it can be sometimes worthwhile renaming the field (just change the word Year to something else).
One other thing worth noting, there are comments starting with
-- integers starting with 0
It was noted on the HHP forum that the IDs in the submission entry example did not match the ids in the data. This is because they started with zeros, so whatever software was used to generate the submission example had treated them as integers and lost the leading zero. Thanks to this I was able to modify my nifty tool to generate warnings if this is the case, and if gives you an alternative if you want to treat the field as a character field, which will preserve the zero.
Leading zeros are sometimes important, as 003 and 03 are not the same, but would become the same if you treated them as integers. I learned this when I used to deal with address files that had postcodes beginning with 0.
Another 'bug' I discovered in my nifty tool was that "55+" passes the isNumeric test (try in an Excel macro - see the sample code at the top of this post) , when it is not really, and SQL Server won't accept it. This improved the tool again, and highlighted the fact that there was some data like this that would need to be closely examined later on.
Running the generated script will load the data and it can then be viewed (click on the image below to see how)
So we are on our way! All the data is in and we can take a peak at it to see what it looks like.
If you want to use niftytools to check and help load data then it is freely available. You will first need to download and install my
Tiberius package, and then look in the program files folder to find it. Note you will need dot net 4 - see
this blog post find out why.